

RでツイッターAPIを使いたい
MeCabで遊んでみたい
ということはありませんか?
この記事では、Rを使って人のツイートを可視化する方法を書いています。
こんなものができます。

人のツイートを可視化するまでの目的・環境
今回の目的
どんな単語をよく使っているのかを調べ、頻度が高い単語を大きな文字で表す。成果物はさっきの通り。
実行環境
- Windows10
- RStudio
- MeCabインストール済み
MeCabをインストールしていない方は、【MeCab】を【R】で使えるようにするための【RMeCab】を導入する方法・流れ【Windows編】の記事をみてください。
RでMeCabを使う方法を書いています。
ツイートを可視化する流れ
超具体的に書いているので、長く感じると思います。実際は簡単なんで心配しないでください。
- TwitterのAPIに登録
- パッケージの導入
- RからTwitterAPIにアクセス
- ツイートの取得
- テキスト部分を取得
- いらない部分の削除
- 文字コード変換
- ファイルの結合と保存
- 名詞・動詞などの残す部分を決める
- 列名の変更
- 一度表にしてみる
- ツイートの可視化
コードを実行していく際、下のようなコードが出るかもしれないけど、気にしないで進んでください。
Warning message:
In strsplit(code, "n", fixed = TRUE) :
input string 1 is invalid in this locale
1.TwitterのAPIに登録
この記事をごらんください。

2.パッケージの導入
必要なパッケージがあります。一気にインストールしてしまいます。
今回必要なパッケージは、これです。
- "wordcoloud"
- "RColorBrewer"
- "RMeCab"
- "dplyr"
- "stringer"
- "magrittr"
- "twitteR"
- "base64enc"
- "bit64"
- "rjson"
- "DBI"
- "httr"
twitteRのパッケージがエラーを起こす可能性があるため、多くのパッケージを入れています。
まだ入れていないパッケージは、インストールしておいてください。
パッケージの導入方法は、【R】RStudioでパッケージをインストールする方法と読み込みまでの流れ
3.RからTwitterAPIにアクセス
TwitterAPIを使うには、次のものが必要となります。
- Consumer Key
- Consumer Secret
- Access Token
- Access Token Secret
わからない方は、【2020年】TwitterのAPIに登録し、アクセスキー・トークンを取得する具体的な方法をご覧ください。
#パッケージの読み込む
library(twitteR)
下に自分のアクセスキー・トークンを入力してね。””は残してね。
consumerKey <- “自分のConsumer Key (API Key)”
consumerSecret <- “自分のConsumer Secret (API Secret)”
accessToken <- “自分のAccess Token”
accessSecret <- “自分のAccess Token Secret”
#認証
options(httr_oauth_cache = TRUE) setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#”Using direct authentication”が表示されたら成功【#】がついているところは、コメントです。実行しないでいいです。
4.ツイートの取得
誰かのツイートを取得していきます。今回はこのアカウント(@gumimomoko)のツイートを取得します。※そのアカウントは存在しないので自由に決めてください。
tweets <- userTimeline(“gumimomoko”, 250)userTimelineでツイートを取得することができます。
【250】は取得するツイート数です。1000ぐらいまでは、さくさく取得できます。
しかし、ここで得られたツイートには、アカウント名や投稿日時などのいらない情報が含まれているの。
5.テキスト部分を取得
texts <- sapply(tweets, statusText)statusTextで、tweetsからテキスト部分を取ろうということです。
6.いらない部分の削除
でもまだ、いらない部分があるの。
library(dplyr)
texts %>% head()2018/02/17時点ではこんな感じになっています。

なんかいらないものが多いでしょ?そこを削除していきます。
#パッケージの読み込み
library(magrittr)
library(stringr)
#いらない記号(ID・URL・記号)を取り除くことができるASCLL
texts %<>% str_replace_all(“\p{ASCII}”, “”)
# 欠損値を省く
texts <- texts[!is.na(texts)]正確に説明するとstr_replace_all("\p{ASCII}", "")は、(ID・URL・記号)を無に変換しています。str_replace_all("A", "B")はAをBに変えるというような、印象をもつとわかりやすいです。
7.文字コード変換
Windowsを使っている方のみ見てください。TwitterAPI(UTF-8)とWindows(CP932)の文字コードが違います。
texts <- iconv(texts , from = “UTF-8”, to = “CP932”)iconv(文字列, from= "変換前の文字コード", to = "変換後の文字コード")
UTF-8 → CP932 にしてます。
8.ファイルの結合と保存
取得したツイートは、バラバラになっています。一つのファイルにしてしまいましょう。
#取得したツイートを一つのファイルにして保存
texts2 <- paste(texts, collapse =””)
#一時的なファイルを作る
xfile <- tempfile()
#先ほどのファイルに結合したツイートを書きだす
write(texts2, xfile)paste(texts, collapse ="")でツイートを一つに結語しています。
例えば、paste("ab", "cd")を実行すると"ab cd"ができます。
tempfile()で一時的なファイルを作っています。
write(texts2, xfile) で先ほど作った一時的なファイルに、結合したファイルを書き出しています。
9.名詞・動詞などの残す部分を決める
とりあえずツイートを一つのファイルにしました。今度は、どこを取り出すかを決めます。
#パッケージの読み込み
library(RMeCab)
cloud <- docDF(xfile, type = 1, pos = “名詞”)
cloud %<>% filter(!POS2 %in% c(“サ変接続”,”非自立”))docDFは名詞とか動詞とか、単語頻度、Ngram頻度などを表してくれる関数です。
今回は名詞を取り除くため、pos = "名詞"にしているよ。
filter(!POS2 %in% c("サ変接続","非自立"))で、サ変接続か非自立を取り除いています。
10.列名の変更
なんか列名が長いです。View(cloud)を実行で、見ることができるよ。
この黄色の部分の名前を変えていきます。

#列名をFREQにする
cloud %<>% select(everything(), FREQ = starts_with(“file”))
#さっき作った一時的ファイルを消す
unlink(xfile)select(everything()ですべての列を取り出しています。
FREQ = starts_with("file"))でfileから始める名前の列を指定して、FREQという文字に置き換えています。
unlink(xfile)でさきほど作ったファイルを消しています。
11.一度表にしてみる
cloud %>% arrange(FREQ) %>% tail(40)これを実行すると、FREQ(頻度が高い単語)順にした、表を表示できます。

12.ツイートの可視化
最後です。
library (wordcloud) wordcloud (cloud$TERM, cloud$FREQ, min.freq = 8,colors = brewer.pal(6,”Set3″))とりあえず表示がこんな感じになります。人によって異なります。

min.freq = 〇はどのぐらいの頻度以上のものを表示するかを表しています。
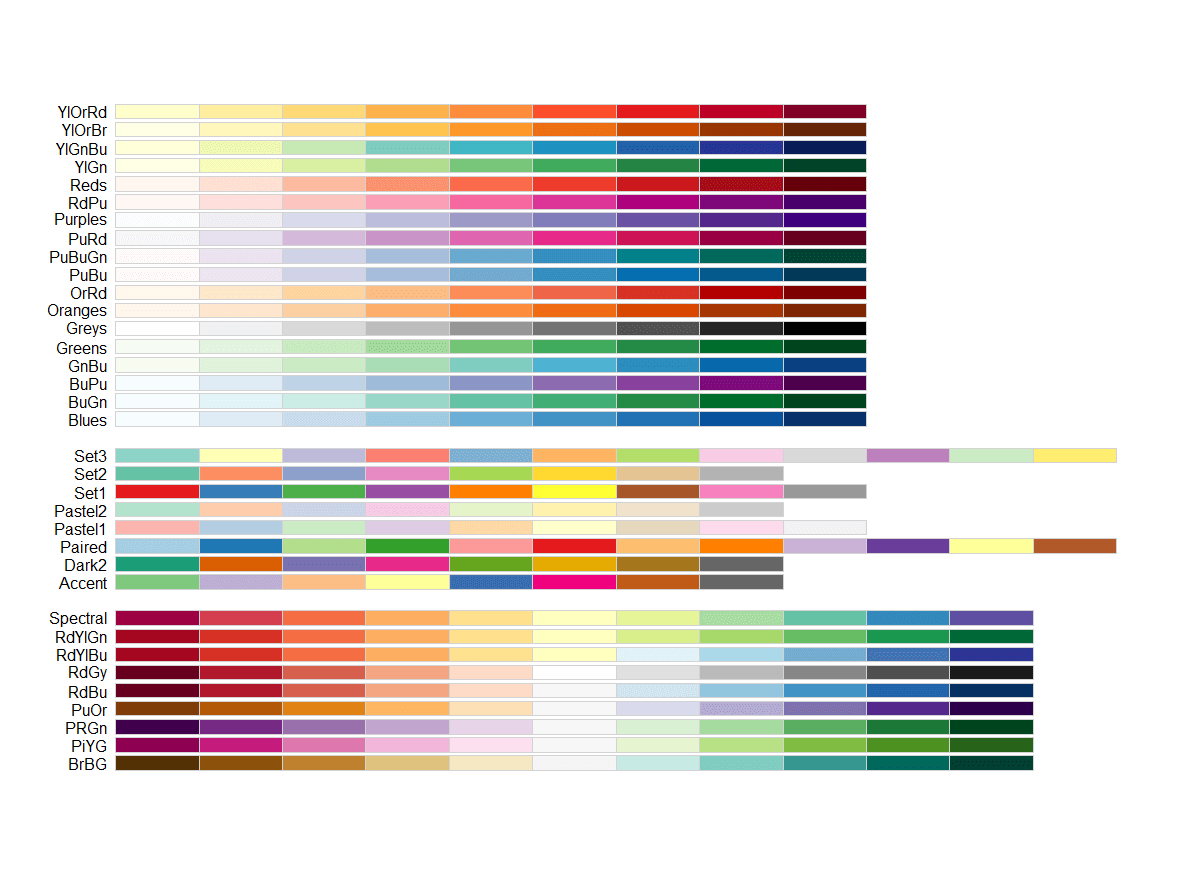
colors = brewer.pal(6,"Set3")ではbrewer.pal(使用色数, パレット名)を表しています。
全体的なコード
部分的なコードで見にくい人はこちらを使ってください。パッケージはインストールしたことは前提です。
#3
#パッケージの読み込む
library(twitteR)
下に自分のアクセスキー・トークンを入力してね。””は残してね。
consumerKey <- “自分のConsumer Key (API Key)”
consumerSecret <- “自分のConsumer Secret (API Secret)”
accessToken <- “自分のAccess Token”
accessSecret <- “自分のAccess Token Secret”
#認証
options(httr_oauth_cache = TRUE) setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#”Using direct authentication”が表示されたら成功
#4
#ツイートの取得
tweets <- userTimeline(“gumimomoko”, 250)
#5
#テキストの部分を取得
texts <- sapply(tweets, statusText)
#6
#いらない部分の削除
library(dplyr)
library(magrittr)
library(stringr)
#いらない記号(ID・URL・記号)を取り除くことができるASCLL
texts %<>% str_replace_all(“\p{ASCII}”, “”)
#欠損値を省く
texts <- texts[!is.na(texts)]
#7
#windowsのみ文字コード変換
texts <- iconv(texts , from = “UTF-8”, to = “CP932”)
#8
#ファイルの結合と保存
#取得したツイートを一つのファイルにして保存
texts2 <- paste(texts, collapse =””)
# 一時的なファイルを作る
xfile <- tempfile()
#先ほどのファイルに結合したツイートを書きだす
write(texts2, xfile)
#9
#名詞・動詞などの残す部分を決める
library(RMeCab)
cloud <- docDF(xfile, type = 1, pos = “名詞”)
cloud %<>% filter(!POS2 %in% c(“サ変接続”,”非自立”))
#10
#列名の変更
#列名をFREQにする
cloud %<>% select(everything(), FREQ = starts_with(“file”))
#さっき作った一時的ファイルを消す
unlink(xfile)
#11
#表を表示してみる
cloud %>% arrange(FREQ) %>% tail(40)
#12
#ツイートの可視化
library (wordcloud)
wordcloud (cloud$TERM, cloud$FREQ, min.freq = 8,colors = brewer.pal(6,”Set3″))まとめ
- TwitterのAPIに登録
- パッケージの導入
- RからTwitterAPIにアクセス
- ツイートの取得
- テキスト部分を取得
- いらない部分の削除
- 文字コード変換
- ファイルの結合と保存[alert title="注意"]ここに文章[/alert]
- 名詞・動詞などの残す部分を決める
- 列名の変更
- 一度表にしてみる
- ツイートの可視化

Udemyというオンライン学習プラットフォームでもR言語について学べます。ぜひ使ってみてください。
参考にした本
RMeCabのパッケージをインストールするところと大まかなTwitterAPIの利用方法は、【Rによるテキストマイニング入門】を参考にさせていただいております。
とてもテキストマイニングをする際に、勉強になる本なので、是非読んでみてください。














コメント